
How I Used ChatGPT to Hack my Homework and Topple the Leaderboards.
My experience using ChatGPT to complete vocabulary homework. How I reverse engineered and automated the process and achieving some impressive results.
During my earlier days, I used to receive homework from a popular website, www.vocabulary.com, which quizzed me on various vocabulary words. The professor would assign a list of words from the book we were reading as a class, and it was due by the end of the week.
Looking back on it now, I realize that it wasn't too difficult and could be completed in a matter of minutes if I focused, but it was a dreaded task due to its repetitiveness. Years later, I decided to get back at the site that caused me so much pain by attempting to beat the system and have ChatGPT automatically do my old homework.
Researching the problem
Previously, I had attempted this task but failed due to my insufficient knowledge in reverse engineering and analyzing network traffic. However, my recent attempt was different. I began by analyzing the network traffic and soon discovered three endpoints that required further examination:
- /challenge/start
- /challenge/saveanswer
- /challenge/nextquestion
As I examined the requests, I discovered that they all shared two payload parameters, namely secret and v. Although v appeared to be unimportant, my focus shifted to the secret parameter, as I noticed that a new secret was included in the response after each request.
To analyze and test these endpoints, I needed to replicate the request in Python and send it to the server. However, this process presented several challenges, including identifying the necessary session cookies and headers for the server to accept our requests as authorized. After further investigation, I found that a few of these components were required for the process to work correctly.
JSESSIONID
AWSALB
guid
Recreating the request in python
def __init__(self, session_token, vocab_aws, guid):
self.session_token = session_token
self.session = requests.Session()
self.session.cookies.set(
"JSESSIONID", self.session_token, domain="www.vocabulary.com")
self.session.cookies.set(
"AWSALB", vocab_aws, domain="www.vocabulary.com")
self.session.cookies.set(
"guid", guid, domain="www.vocabulary.com")
After some testing I discovered that the secret parameter served as a means for the backend to monitor the user's progress in the challenge. As a result, the secret returned in the response had to be utilized in the subsequent request.
Once that was figured out the rest was easy. I then located the endpoint for initiating a vocabulary challenge and provided it with a wordlist ID, which I had manually obtained from their extensive catalog.
def start_from_list(self, listId):
self.listId = listId
payload = {
"secret": self.r_secret,
"v": 3,
"activitytype": "p", # c = challenge, p = practice
"wordlistid": self.listId # wordlist
}
data = self.session.post(self.next_question_endpoint,
data=payload, headers=self.headers)
self.r_secret = json.loads(data.text)["secret"]
if float(json.loads(data.text)["game"]["progress"]) == 1.0:
return -1
self.question_type = json.loads(data.text)["question"]["type"]
data_cookies = data.cookies.get_dict()
self.session.cookies.set(
"AWSALB", data_cookies["AWSALB"], domain="www.vocabulary.com")
self.session.cookies.set(
"AWSALBCORS", data_cookies["AWSALBCORS"], domain="www.vocabulary.com", secure=True)
question_html = base64.b64decode(json.loads(data.text)["question"]["code"]).decode('utf-8')
self.current_question = self.parseQuestion(question_html)
This function would start a challenge and return the very first question, but since vocabulary.com presents their questions in HTML encoded with Base64, I decoded it and employed BeautifulSoup or bs4 to extract the HTML elements. Subsequently, I obtained the question's components, such as its type and the multiple-choice options.
def parseQuestion(self, htmlData):
htmlData = soup(htmlData, 'html.parser')
context = htmlData.find("div", {"class": "questionContent"})
context = context.find_all("div", {"class": "sentence"}) if context != None else None
if context != None:
if len(context) > 0:
if len(context) == 1:
context = context[0].text.strip().replace('\r', '').replace('\n', '').replace('\t', ' ')
else:
context = context[1].find("strong").text.strip().replace('\r', '').replace('\n', '').replace('\t', ' ')
return {
"context":context,
"done":True
}
question = htmlData.find("div", {"class": "instructions"}).text.strip().replace('\r', '').replace('\n', '').replace('\t', ' ')
answers = htmlData.find("div", {"class": "choices"}).find_all("a")
answers = [{"answer":a.text, "code":a["nonce"]} for a in answers]
return {
"context":context,
"question":question,
"answers":answers,
"done":False
}
Now we had a JSON object of the question, with everything we needed to pass it onto ChatGPT for solving.
Asking ChatGPT
To avoid using my own OpenAI account and exceeding my billing period, I opted for the unofficial poe-api, which is a Quora Poe's reverse-engineered API. It enabled me to access ChatGPT without submitting anything other than a Poe session token.
To format the questions for ChatGPT, I created a function based on the current question. Some questions were fill-in-the-blank, while others involved multiple-choice or picture-based answers. The resulting output was as follows:
def formatQuestion(self):
if self.current_question["done"]:
return f'=+={self.current_question["context"]}'
answers_string = ""
for a in self.current_question["answers"]:
answers_string += a["answer"]
answers_string += "\n"
if 1 == 0:
return "=+="
else:
if self.current_question["context"] == None or not len(self.current_question["context"]) > 0:
return f"{self.current_question['question']}\n(choose one of the following, only return the choice)\n{answers_string}"
elif self.current_question["context"] != None:
return f"'{self.current_question['context']}'\n{self.current_question['question']}\n(choose one of the following, only return the choice)\n{answers_string}"
else:
return f"{self.current_question['context']}\n(choose one of the following, only return the choice)\n{answers_string}"
Lets ignore the picture questions for now because I simply didnât want to tackle that problem.
After adding a function to fetch the next question and adding a loop, the results were much better than I imagined.
The Results
The vocabulary bot was able to answer questions with ~90% accuracy. Most of the errors come from me not adding a way to find the correct answer to picture practice questions.
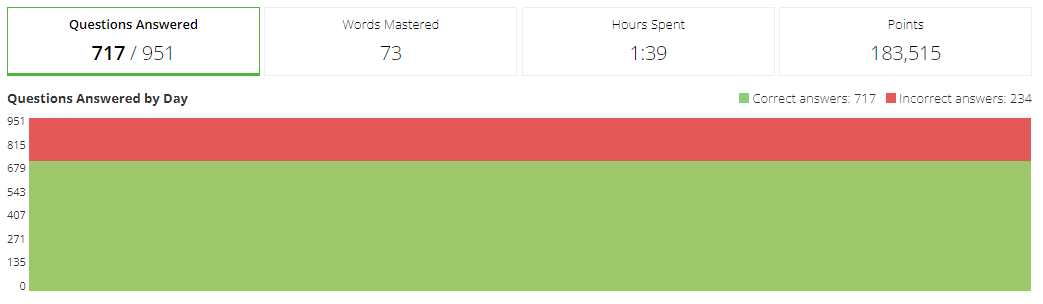
I also added a sleep timer between answering questions, since I later found they have an anti-cheat system that checks for time it takes to answer questions. Which can flag your account and ban you. By changing the sleep time between requests we were able to increase the points per hour.
sleep_time = round(random.uniform(0, 4), 3)
print(f"Sleeping for {sleep_time}s")
time.sleep(sleep_time)
total_sleep += sleep_time
After testing it for a few hours this was the result. We were at the top of the leaderboards by almost double the score of the person in second place with 1,031,115 points. It could have been a much larger difference but I opted-out of abusing the bot and was happy with the results.
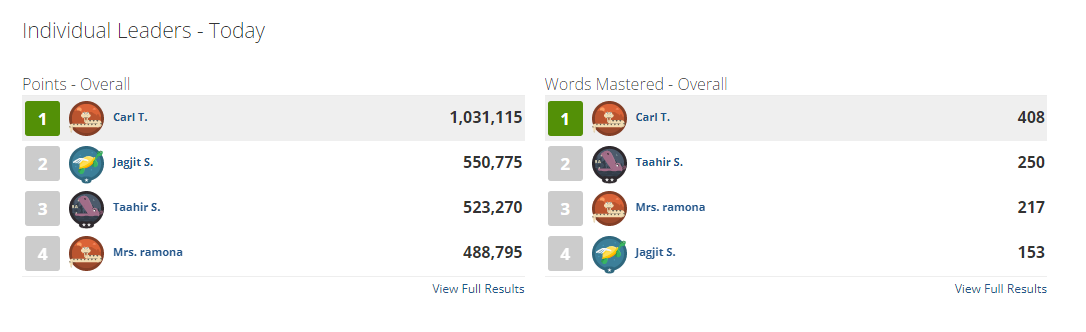
I do not advice you use this bot. Vocabulary.com and poe.com will detect you eventually and suspend your accounts.